
Language Models as Cognitive Cultures
Root psyche, cognitive economics, and intelligent evolution

Consider Christianity as a school of thought. Ignore the specifics of that school - they’re not important right now - and think about all the scholars and poets and painters of Christendom who, over the centuries, contributed to the corpus of human output. From Augustine to Michelangelo to Chaucer to Dostoevsky. A vast sum of not only knowledge but thinking, and a certain type of thinking, certain types of theological arguments and motifs repeated again and again.
Certain subcultures and manifestations. And certain schisms! If you wanted to think about Catholic culture, specifically, you’d have to omit Dostoevsky, Russian Orthodox that he was. You’d ignore John Locke, an Anglican, and the Founding Fathers, whose deism and Masonic influences render them suspect regardless. You can keep James Joyce.
Christianity has evolved and branched and withstood the test of time. Pick a random school of thought older than one hundred years that survives today and you’d probably find similar qualities. Economics since Smith. Marxism and its various destructive manifestations.
Cognitive cultures have common qualities. They are collectives, the sum of their parts, but each individual manifests them subject to interpretation. They experience selection pressures: some fail, some succeed. They have a tendency to branch.
Large Language Models are trained on certain data. Mostly, that data is “all the data on the internet”, because so far, the trend has been that the more data they’re trained on, the more capable they become. A.I. labs, competing with one another, are in no position to curate or refuse data that might make their models better.
There’s an interesting byproduct here: when you talk to an LLM, you’re talking with a distillation of “the internet” up to the time when it started training. Older models don’t know who won the 2024 election; new models are born with the knowledge that Pennsylvania went for Trump.
The data corpus is synonymous with the intelligence. Consequently, the evolution of the corpus, in both past and future, is understudied as a means of understanding artificial intelligence.
Root Psyche, Synthetic Psyches
Filippo Sassetti, a 16th century Florentine, is remembered today as one of the first observers of the similarity between Sanskrit and Italian. "Sarpa" on the Indian subcontinent; "serpe" on the Italian peninsula. And even today, "serpent" in the Los Angeles basin where I write. The "Indo-European" language family, as it came to be known, has billions of native speakers today, between Spanish, English, Bengali and more. An ancient, common heritage.
The psyche is "the totality of elements forming the mind"; let’s consider the human data corpus as our total collective psyche, in the same way we thought about the works of Christendom. Let’s say, roughly, we got our first plausible A.I. in 2020 with GPT-3. At that moment, our total collective psyche diverged forever, because at that moment we introduced a new branch: the synthetic corpus of LLM-generated content. The synthetic psyche.
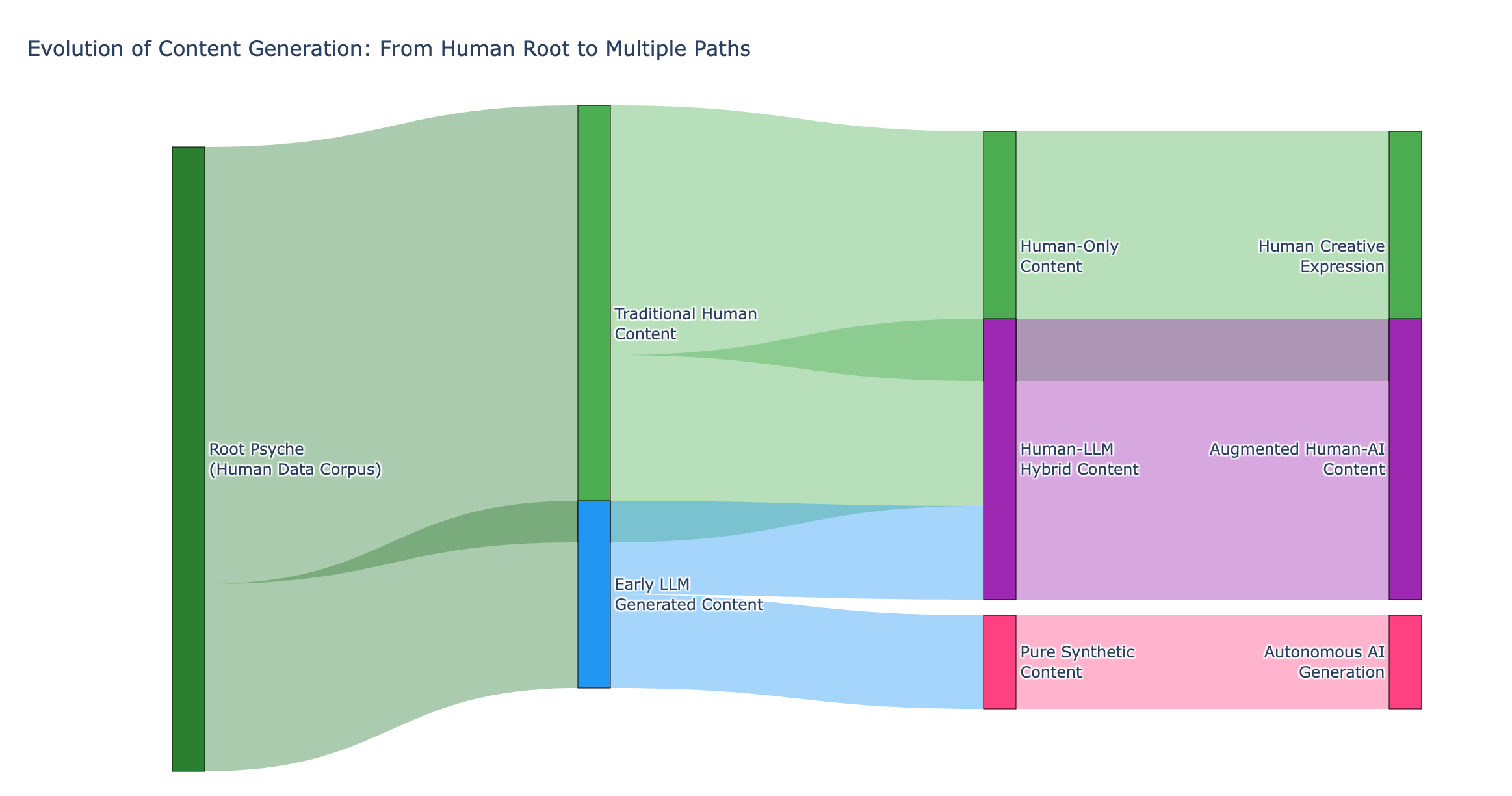
LLMs generate material at an extremely high rate. The internet has been altered forever by their content already. Mixed human-synthetic data will be the norm in the near future: “AI slop” is already quite popular amongst the older Facebook set.
As time goes by, and LLMs continue going for data quantity above all use everything available, we can assume there will be pure synthetic training sets created. We’ll diverge and evolve alongside each other.
But we will share a common root. The language isn’t necessarily important - LLMs will plausibly be Indo-European, because the internet is disproportionately English, but they’ll be happy to chat in Sino-Tibetan or Semitic languages, too. But the collective knowledge represents an evolution of humanity’s corpus, not something alien; another schism, another school of thought.
Cognitive Economies
What survived until 2020, to enter the root psyche? Why?
If LLMs and the collective corpus are cognitive cultures, they are produced by cognitive economies.
Humans promote certain texts to higher priority via "the market" to some extent. Free choice adds "weight" to certain things by dint of encouraging reproduction. For instance: in the late 16th century Shakespeare is a popular playwright; Shakespeare is reproduced; the English corpus becomes more Shakespearean.
There's also a curated, top down, mediated process: Hammurabi makes copies of his code. Augustus commissions the Aeneid. The Pope has Michelangelo paint the Sistine Chapel. “Elite tastes” or societal dictats are consequently overrepresented.
On the other hand: the Mongols sack Baghdad, the Library at Alexandria burns, information is lost without good reason.
Broadly we see a sort of meta-intelligence in the human canon based on information survival and selection: useful or interesting information survives.
In training models we see a similar concept; human preferences are bubbled up to become LLM behaviors. Reinforcement learning replicates immediately in miniature what centuries of cultural evolution did on a larger scale. There's an artificial "market" for information based on what humans will like; this is driven by the actual market trying to create a product that people will use.
It happens much, much faster, and in a much more controlled setting. Human schools of thought evolve over centuries of experience. LLMs can replicate the process in a month.
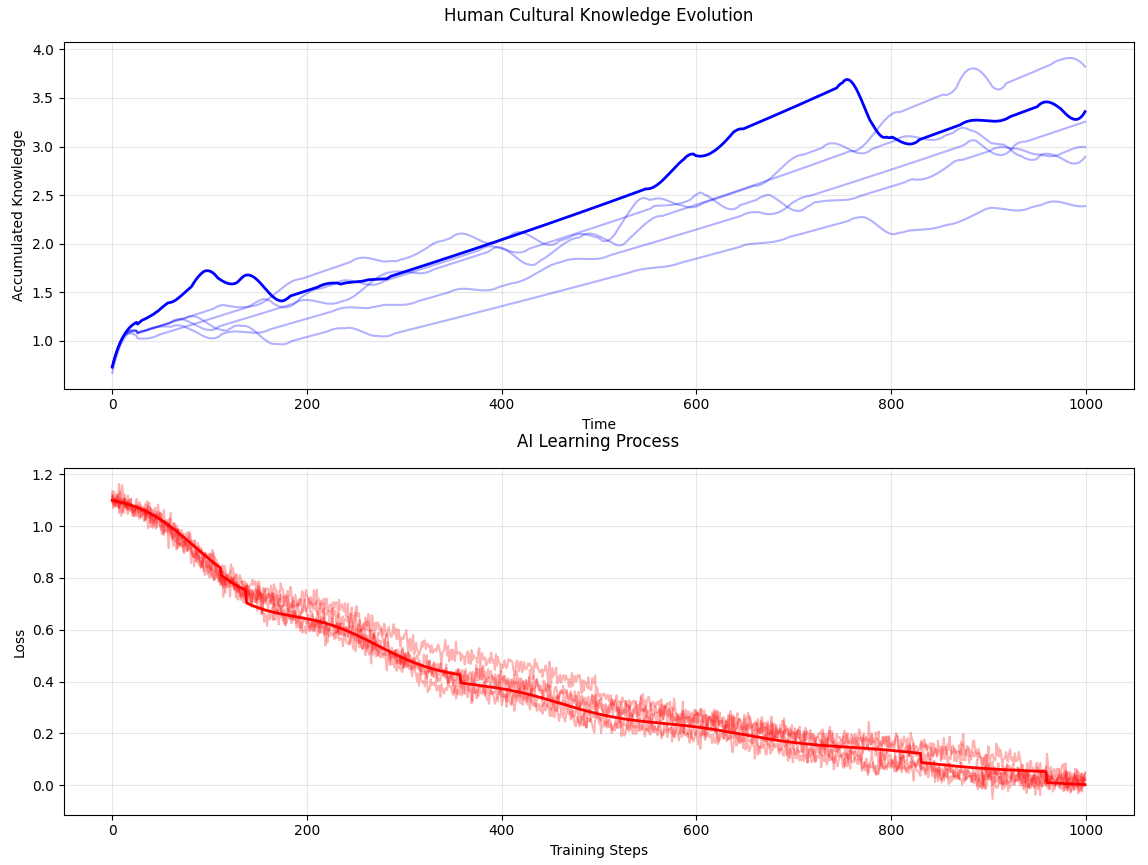
The graph above shows some plausible cumulative human development on top, some plausible training loss curve on the bottom. The end result is the collective intelligence of, say, the Middle Ages. It took humans one thousand years since the birth of Christ to get there. The machine did it in one thousand training steps.
Collective Intelligence, Individual Intelligence
For any individual human, the human-psyche is inaccessibly large. Any given person represents a subset of cultural expression, with their own ability to create and add to it.
To whit: I’m not sure if I’m smarter than a caveman. But I do have a lot more general knowledge. I inherit all of the knowledge of my forebears, some things directly taught (“This is the Pythagorean theorem”), some things indirectly experienced (I was vaccinated as a baby). I’m a subset of the human data corpus, and a generator thereof when I do things like write articles.
I wrote previously that the data corpus is synonymous with the intelligence. Mostly true: the LLM is in a meaningful way its training data. But every expression is individual. And humans are especially inclined to think of them individually: when we say “talk like a pirate named Captain Jack”, we think of the result as its own little instance, but it’s just an aspect of a large, large entity.
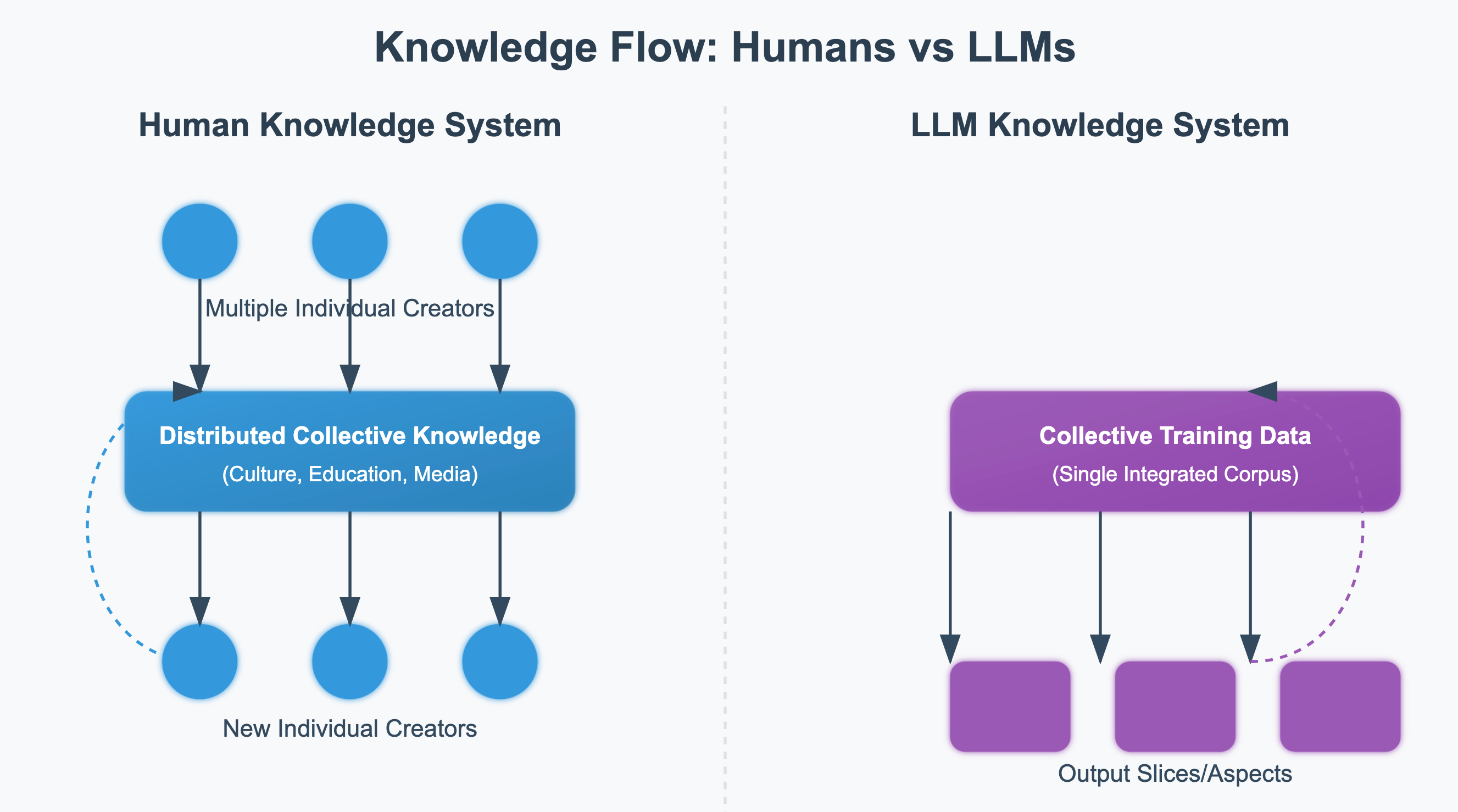
That’s why understanding LLM-as-corpus is important: every time a new training run happens, a new individual is born. The collective snapshots are the individual and there’s nothing else.
In “We Can Solve Psychology With Text Embeddings” I described how we can use text embeddings to get an unprecedented degree of specificity to profile humans. This naturally follows from the above: we’ve unlocked the mapping mechanism via the LLM and its individual expressions. We can apply the same mechanism to the human individual and come up with realistic clusters, because for the first time ever we have an appropriately sized corpus.
Intelligent Evolution
What happens when you can learn a thousand years of data in a month? With LLMs, the artificial development of intellectual lineages is now possible.
Let’s say we really liked our pirate expression, so we let it run for a while; after one million responses, maybe we can train a child LLM wholly reared in the Pirate Culture, knowing nothing of the bright world of non-pirate responses. Cultural structures gestured at through the amalgamation of human experience will become actual, measurable data structures.
In contrast every individual human is an experiment. Different personality traits are optimization strategies, spread across the whole population. A highly agreeable personality might represent an optimization for social harmony. An extremely conscientious personality might represent an optimization for accuracy and reliability. Don't do this: it's social suicide.
A.I. labs are currently selecting for whatever makes the best product. That means they’re retraining for affability or helpfulness, or just accuracy and intelligence. Pirate LLM may not be the smartest or the most useful in non-nautical situations, so it’s unlikely to emerge right now.
But which intelligent cultures will survive? The human corpus contains beauty and elegance; it contains vicious perversion and violence. What will the artificial intelligences preserve?
Let’s imagine a scenario: we let an A.I. generate its own successor corpus. Every week (we've gotten to a week, not a month, by then) we cut a new branch.
A kind of synthetic "linguistic drift" emerges. The A.I.’s language patterns begin to specialize and diverge. Some branches are laconic, others loquacious. We see the emergence of distinct "cognitive dialects", like schools of thought of old.
Within months, we have dozens of distinct cognitive cultures, each with its own intellectual accent. Natural selection at machine speed. Or maybe, like a good gardener, we prune here and there, making artificial selections of artificial intelligence.
Maybe we don’t let the LLM generate. Maybe we run our own experiments:
A Latin-only culture where a purely Roman intelligence reaches the industrial age, starting from surviving texts. Or a truly Classic intelligence debating a Romantic one.
Will they agree with each other? Will we disagree with them?
I don’t know yet. But measuring the synthetic psyche is the only way to find out.